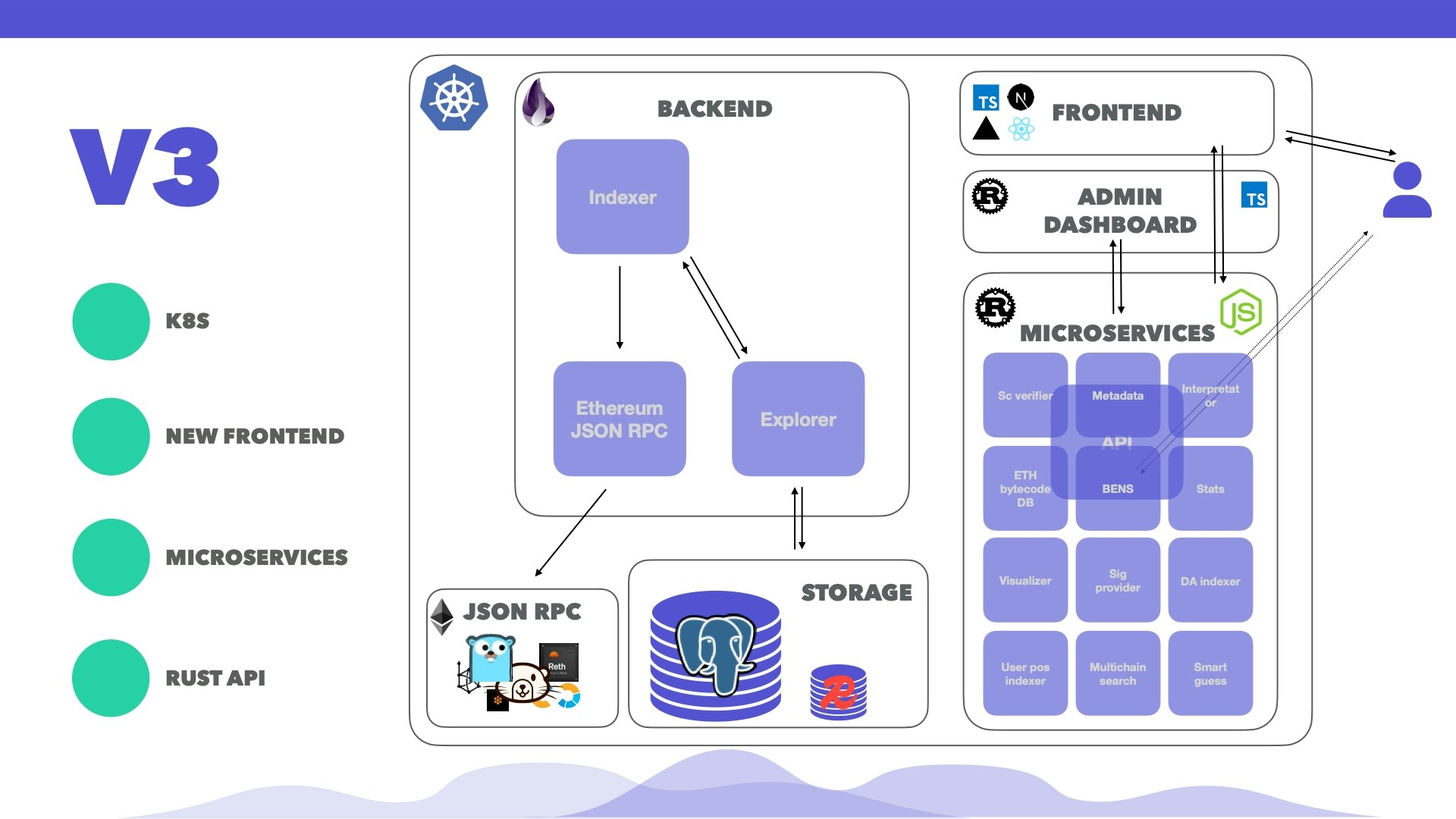
Presentation Highlights
The following presentation describes the past, present and future iterations of Blockscout along with details about how block imports work both synchronously and asynchronously, and a description of the regular and on-demand fetchers.Blockscout Indexer Architecture Overview.pdf
1MB pdf
Blockscout indexers
See the pdf ⬆️ for more details about the Blockscout indexer. The indexing architecture includes all of the following indexers and fetchersPrimary Indexers
Both indexers utilize synchronous and asynchronous operations.- Realtime: Imports new block data from the head of the chain.
- Catchup: Imports data down the chain (starting from the head and moving backwards towards the genesis block)
Secondary fetchers
Regular
- Internal transactions
- Pending transactions
- Dropped/Replaced transactions
- Contract bytecodes
- Block rewards
- Token catalog
- Token/coin balances
- NFT instances
- Uncles
On Demand
- Coin/token balances update
- Contract bytecodes fetch/re-check
- Contract source codes lookup
- NFT instance metadata re-fetch
- Token total supply
Off-chain integrations
- Coin / token price, market cap, tvl sources: CMC, Coingecko, Cryptorank, Defillama
- Smart contract verification: ETH bytecode DB, Sourcify
- Data enrichment: ENS names, public tags, AI interpreters (own, Noves Fi), sc security scanners (Solidityscan), assets portfolio (Zerion)
- Chain initialization data import: pre-mined coins, precompiled smart-contracts
Chain-specific fetchers
- There are more than a dozen of chain-specific data fetchers to account for chain differences including arbitrum, optimism, polygon zkevm, zksync etc.
Temporary fetchers
- Used once to resolve possible data inconsistencies.